
📖 CCP-Based Estimation#
⏱ | words
Integrated \(\ne\) expected value function#
Maintain the setup of from the Zurcher engine replacement model of Rust [1987], leaning to more generality..
The Bellman equation of the Zurcher problem is
The last equation uses the EV1 assumption on the distribution of \(\varepsilon\), but in more generality can be written as
Let’s repeat the terminology:
\(v(x,d)\) is choice-specific value function or conditional value function
\(EV(x,d)\) is commonly referred to as the expected value function and sometimes as ex-post value function
And here is a new object and yet another representation
\(V_\sigma(x)\) is the integrated value function also known as the ex-ante value function
\(\sigma\) is involved following the notation of Aguirregabiria and Mira [2007] who define it as the value function under a strategy profile \(\sigma\)
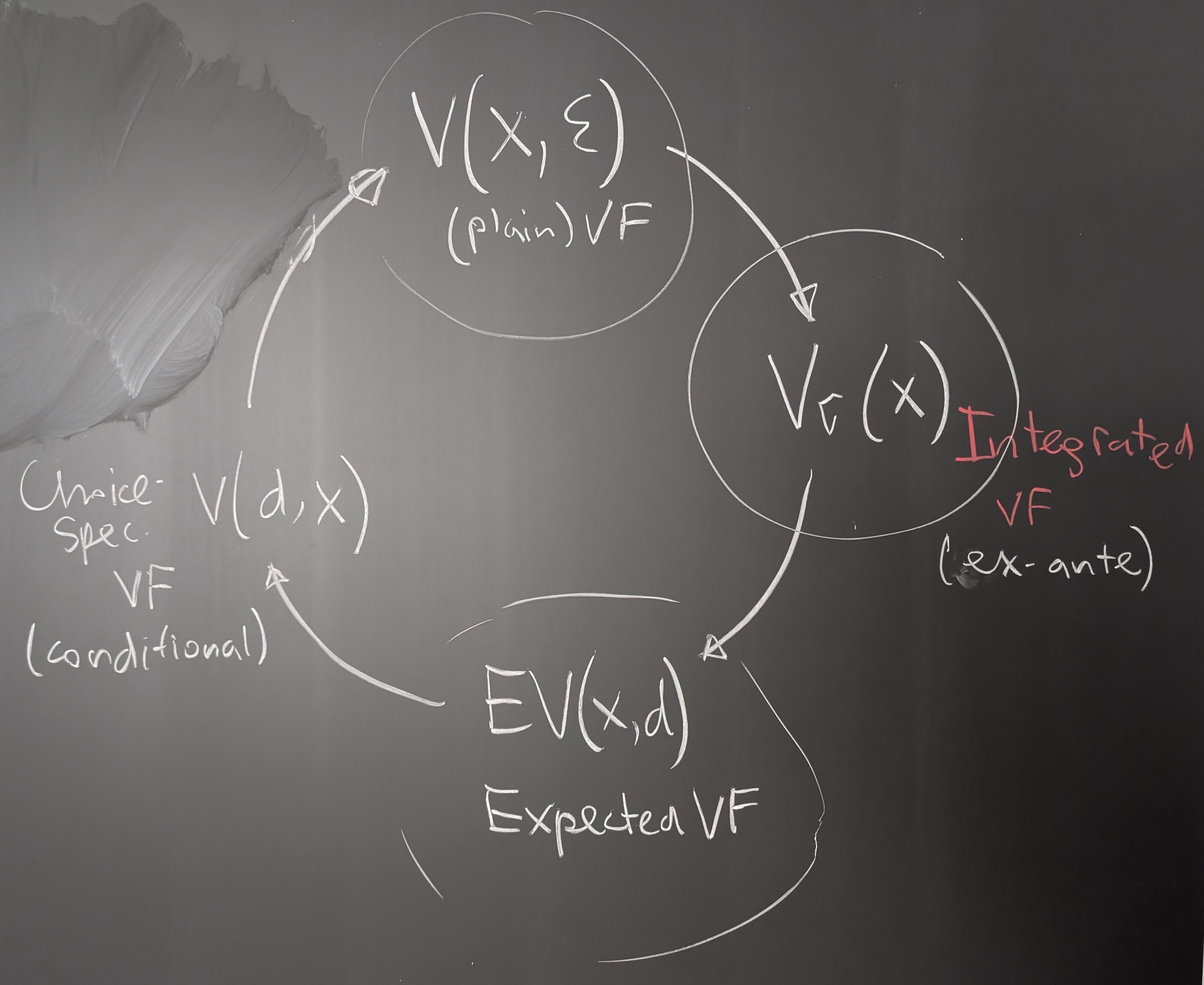
Fig. 1 The Bellman circle of value functions: plain value function \(V(x,\varepsilon)\), integrated value function \(V_\sigma(x)\), expected value function \(EV(x,d)\) and choice-specific value function \(v(x,d)\)#
We could write the Bellman equation in the space of integrated value functions \(V_\sigma(x)\) by cutting the circle of Bellman at a different point:
\(\dots\) \(\rightarrow\) \(V(x,\varepsilon)\) \(\rightarrow\) \(V_\sigma(x)\) \(\rightarrow\) \(EV(x)\) \(\rightarrow\) \(v(x,d)\) \(\rightarrow\) \(V(x,\varepsilon)\) \(\rightarrow\) \(\dots\)
The new representation of the Bellman equation is:
This is the expectation of the maximum utility in RUM with alternative utilities given by \(v(x,d') + \varepsilon_{d'}\)!
McFadden [1974] called this function the Social Surplus Function.
In the EV1 case we simply have due to max-stability, with \(\gamma \approx 0.5772\) being the Euler-Mascheroni constant
Choice probabilities#
Recall that by the Williams-Daly-Zachary Theorem in the general case the choice probabilities can be written as
And under EV1 assumption
Inversion theorem#
📖 Hotz and Miller [1993] “Conditional Choice Probabilities and the Estimation of Dynamic Models”
Let \(d_0\) denote the reference alternative \(\rightarrow\) the values of other alternatives will be measured relative to it
Why?
For each \(x\) consider the vector of value differences \(\Delta v(d,x) \in \mathbb{R}^{K-1}\) where \(K=|D(x)|\) is the number of alternatives. The elements of this vector are
Another way to express the choice probabilities \(P(d|x)\) is through the integral with respect to the distribution of \(q(\varepsilon|x)\)
Compare this derivation to: Static multinomial logit model
In other words if
is a mapping from \(K-1\) value differences to the \(K\) vector of probabilities, then the choice probabilities are given by
Inversion Theorem
Under certain regularity conditions on \(q(\varepsilon|x)\) the mapping \(Q_d\) is invertible, i.e. there exists a mapping \(Q_d^{-1}: [0,1]^{K} \ni P \mapsto \delta \in \mathbb{R}^{K-1}\) such that
Example
In the multinomial logit case for some \(d_0 \in D(x)\)
The inverse map is given by
What we have:
Hotz-Miller inversion gives a mapping from the choice probabilities to the value differences for any choice model with random terms \(\varepsilon\) satisfying the regularity conditions of the theorem
In the EV1 and GEV cases we have a closed-form expressions for the inverse map
Relationship between \(V_\sigma(x)\), \(v(x,d)\) and choice probabilities#
Recall that the choice probability \(P(d|x)\) in general case are simply the expectation of the indicator that a particular choice \(d\) maximizes yields maximum utility
The last expression for \(V_\sigma(x)\) can be expanded using the law of iterated expectations as
The term
has special name of correction term, see Arcidiacono and Miller [2011], which is equal the expectation of the random component conditional on the event that the alternative it is associated with has the highest value. We end up with
We can make one more step, using the Hotz-Miller inversion with a reference alternative \(d_0\), to arrive at
where \(\psi(d,x)\) is a function of the choice probabilities and not the value functions as shown by Arcidiacono and Miller [2011]
In other words, the difference between the integrated value function and any choice-specific reference value is a function of the choice probabilities only!
Special case of EV1 and GEV#
Arcidiacono and Miller [2011] show that
where \(N(d)\) is the set of alternatives in the same nest as \(d\) and \(\gamma\leqslant 1\) is the EV scale parameters within the nest.
Some words on identification#
Previous results have immediate implications for identification of the model primitives for the dynamic discrete choice models in general
We are interested in non-parametric identification of the model primitives \(\{u, \pi, q, \beta)\) given the data on \((x,d)\)
Here is a brief sketch
Assume discrete state space \(\rightarrow\) integral over \(\pi(x'|x,d)\) is a sum and can be represented by a matrix multiplication. Denote \(\Pi(d)\) the transition probability matrix for the state space \(X\) under action \(d\).
First, we can consistently estimate the choice probabilities \(P(d|x)\) — CCPs — and the transition probabilities \(\Pi(d)\) from the data on \((x,d)\) in the fist stage, giving the name to the corresponding CCP-based estimation methods.
Then, fix the reference alternative \(d_0\) and set \(u(d_0,x) = 0\) for all \(x\).
Stack all entities into vectors over the state space \(X\) to obtain
From the relationship between \(V_\sigma(x)\) and \(v(x,d)\) we have
This is an expression for the integrated function that only depends on objects we can estimate in a first stage
To non-parametrically estimate the utility function for the other actions, follow
Given \(\beta\) and \(q\) the utility function \(u(d)\) seem to be non-parametrically identified for all \(d \in D(x)\)
However, if we don’t assume \(u(d_0)=0\) and run through the same derivation again, we will end up with
and the obtained values of \(u(d)\) will perfectly consistent with the observed data informing \(P(d|x)\) and \(\Pi(d)\)!
Normalization is needed unless some data informs the level of utility (e.g. data on costs or prices)
We may also resort to parameterized utility function
Side note: Normalizing the value of an alternative to zero is common but not innocuous, see Kalouptsidi et al. [2021]
Finite dependence#
Finite dependence is a powerful idea that helps identification and estimation
In many applications there may be different paths from a points in the state space \(x_1\) and time period \(t_1\) to he point \(x_2\) and time period \(t_2\)
Two different paths require different sequences of choices
Yet, at \(x_2\) and time period \(t_2\) the future should look exactly the same regardless of the path taken to get there
\(\implies\)
The expected values at \(t_2\) can be differenced out \(\rightarrow\) resulting in a finite structure of dependence with no need for matrix inversions!
Similar to finite horizon problems.
Example
Zurcher model has one-period finite dependence!
Indeed, all regenerative models have this property: renewing today leads to exactly same future outlook as renewing one period later (and here exact time subscripts do not matter due to stationarity)
CCP-based estimation#
There are many estimation approaches based on the CCP representation of the dynamic discrete choice models
Minimum distance [Altuğ and Miller, 1998]
Simulated moments [Hotz et al., 1994]
Asymptotic least squares [Pesendorfer and Schmidt-Dengler, 2008]
Quasi-maximum likelihood [Hotz and Miller, 1993]
Pseudo-maximum likelihood [Aguirregabiria and Mira, 2002]
Nested pseudo-likelihood [Aguirregabiria and Mira, 2007]
Many-many more
Common scheme:
Estimate the CCPs \(P(d|x)\) and transition probabilities \(\Pi(d)\) directly from the data on \((x,d)\)
Non-parametrically like frequency counts
Parametrically like multinomial logit or nested logit for \(P(d|x)\) and discrete choice model for \(\Pi(d)\)
Semi-parametrically like flexible or local logit
Use the estimated CCPs and transition probabilities to construct a criterion function that depends on the structural parameters of the model \(\theta\)
Optimize the criterion function to obtain the estimates \(\hat{\theta}\) by one of the above approaches
What are the strengths of CCP-based estimation? How does it compare to NFXP?
What are potential weaknesses and difficulties of this approach?
Quasi-likelihood estimation#
Like all CCP-based methods, the quasi-likelihood estimation starts with the consistent estimation of the CCPs and transition probabilities from the data. Let’s focus on the specification of the statistical criterion for the second stage. Return to
Using the definition of the choice-specific value functions we have
Again, assuming discrete state space and stacking \(V_\sigma(x)\), \(P(d|x)\), \(u(x,d)\) and \(e(x,d)\) across the state space to form column vectors, we can write the last equation for every point of the state space in a matrix form
where \(\ast\) is the element-wise (Hadamard) product of vectors. Let
be a \(|X|\times|X|\) unconditional transition matrix, and denote \(I\) again the identity matrix of the same size, then
Recall that the correction term \(e(d)\) is a function of the CCPs only, and therefore we can introduce an operator
that maps the CCPs into the integrated value functions.
Finally, denote
the mapping from the integrated value functions to the CCPs given by the choice probability formulas above, which in the simple EV1 case take the form of multinomial logit
Following Aguirregabiria and Mira [2007] we define the composition operator as
which maps the CCPs into the CCPs through the integrated value functions.
Note that \(\Psi\) depends on the structural parameters of the model \(\theta\) through \(u(x,d)\) and \(\beta\)
Resulting algorithm:
First stage CCPs and transition probabilities estimates \(\hat{P}(d|x)\) and \(\hat{\Pi}(d)\) for all \(x\) and \(d\)
Specify a quasi-likelihood function based on the estimated CCPs and transition probabilities
where \(\Psi(\hat{P},\theta)\) is an operator given above. The quasi-likelihood function can be specified as
and the quasi-maximum likelihood estimator is given by
Swapping NFXP: NPL estimator#
📖 Aguirregabiria and Mira [2002] “Swapping the Nested Fixed Point Algorithm: A Class of Estimators for Discrete Markov Decision Models”
Aguirregabiria and Mira take this idea a step further and develop the nested pseudo-likelihood (NPL) estimator which is nothing else but iteration of the quasi-likelihood estimator:
This is an intuitive definition of the NPL operator, the fixed point of which provides an NPL estimator:
converges to MLE NFXP estimator as number of iterations increases
each iteration is computationally cheap
bridges the gap between CCP two-step estimator and NFXP
Further topics#
CCP estimation approach gave rise to a number of further avenues of methodological research and applied work
Unobserved heterogeneity among decision-makers Arcidiacono and Miller [2011]
Developed theory of representation with connection terms
Expectation-maximization algorithm
Computational finite dependence
find and exploit finite dependence structure in applications by comparing distributions of future states in different points of the state space
Identification literature
Discount factor by Abbring and Daljord [2020]
Special cases and circumstances
References and Additional Resources
📖 Hotz and Miller [1993] “Conditional Choice Probabilities and the Estimation of Dynamic Models”
📖 Arcidiacono and Miller [2011] “Conditional Choice Probability Estimation of Dynamic Discrete Choice Models With Unobserved Heterogeneity”
📖 Arcidiacono and Miller [2019] “Nonstationary dynamic models with finite dependence”
📖 Aguirregabiria and Mira [2002] “Swapping the Nested Fixed Point Algorithm: A Class of Estimators for Discrete Markov Decision Models”
📺 Econometric Society Dynamic Structural Econometrics (DSE) lecture by Robert Miller YouTube video