
📖 Consumption-savings models#
⏱ | words
Continuous rather than discrete choice
Solution approaches?
Estimation method?

Cake eating#
Let’s start with a toy consumption-savings specification to get some intuition.
Choices of the decision maker
How much cake to eat
State space of the problem
A full list of variables that are relevant to the choices in question
Preferences of the decision maker
Utility flow from cake consumption
Discount factor
Beliefs of the decision agents about how the state will evolve
Transition density/probabilities of the states
May be conditional on the choices
Notation:
Cake of initial size \(W_0\)
How much of the cake to eat each period \(t\), \(c_t\)?
Time is discrete, \(t=1,2,\dots,\infty\)
What is not eaten in period \(t \) is left for the future \( W_{t+1}=W_t-c_t\)
Preferences for the cake#
Let the flow utility be given by
Overall goal is to maximize the discounted expected utility
Value function#
Value function \( V(W_t) \) = the maximum attainable value given the size of cake \( W_t \) (in period \( t \))
State space is given by single variable \( W_t \)
Transition of the variable (rather, beliefs) depends on the choice
Bellman equation#
Bellman operator#
With infinite horizon (\(T=\infty\)) the Bellman equation becomes a fixed point equation for a particular operator in functional space
The Bellman equations is then \(V(W) = T({V})(W)\), with the solution given by the fixed point
Recall the dynamic programming theory: Bellman operator is a contraction mapping by Blackwell sufficient condition, and therefore the fixed point can be found by successive approximations algorithm, also known as value function iterations (VFI).
The question with the continuous choice models is how to numerically implement the Bellman operator.
Maybe we can find analytic solution?#
Cake eating model turns out to admit a nice analytical solution!
Start with a (good) guess of \( V(W)=A+B\log W \)
Determine \(A\) and \(B\) and find the optimal rule for cake consumption.
This guess-and-verify approach requires a good intuition and only works in a handful of models.
F.O.C. for \(c\)
Then we have
After some algebra
Great! Having analytical solution allows to measure errors in the numerical solution perfectly.
Solution methods#
Could we use the save discrete techniques in continuous choice models? What are advantages and disadvantages?
Approach 1: Discretizing continuous choice#
Discretize the continuous state variable \(W\)
Discretize the continuous choice variable \(c\) as well
Advantage: easy computation of maximum in the Bellman equation (also robustness to local maxima in non-convex problems)
Disadvantage: severe loss of accuracy when choice grid is insufficient
Lets see.
Construct a grid (vector) of cake-sizes \( \vec{W}\in\{0,\dots\overline{W}\} \)
Compute value and policy function sequentially point-by-point
May need to compute the value function between grid points \( \Rightarrow \) Interpolation and function approximation
Avoiding interpolation#
But we could avoid interpolation by rewriting
Can replace \( c \) with \( W_{t+1} \) in Bellman equation so that next period cake size is the decision variable
Compute value and policy function sequentially point-by-point
Note that grid \( \vec{W}\in\{0,\dots\overline{W}\} \) is used twice: for state space and for decision space
Can you spot the potential problem?
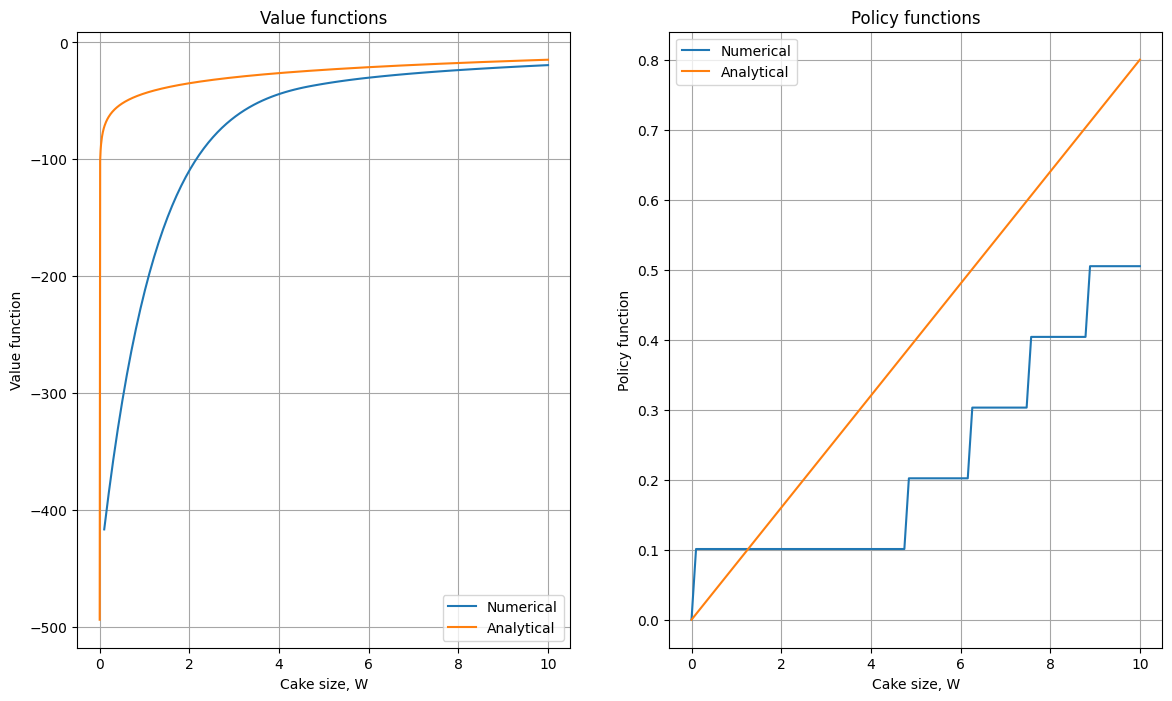
With secondary choice grid#
Clearly, reusing the same grid for state and choice is a bad idea which leads to a drastic loss of accuracy!
We should control for grid over state space separately from the discretization of the choice variables to increase accuracy.
Discretize state space with \(\vec{W}\in\{0,\dots\overline{W}\}\)
Discretize decision space with \(\vec{D}\in\{0,\dots\overline{D}\}\)
We could set \(\overline{D}=\overline{W}\), but much better is to use \(\overline{D} = \vec{W}_j\) for each point of the state space \(\vec{W}_j\) to explicitly respect the \(0 \le c \le W\) constraint (controlled by the optim_ch argument in the example)
Complication: have to interpolate the computed on the previous iteration value and policy functions between the points of the state grid.
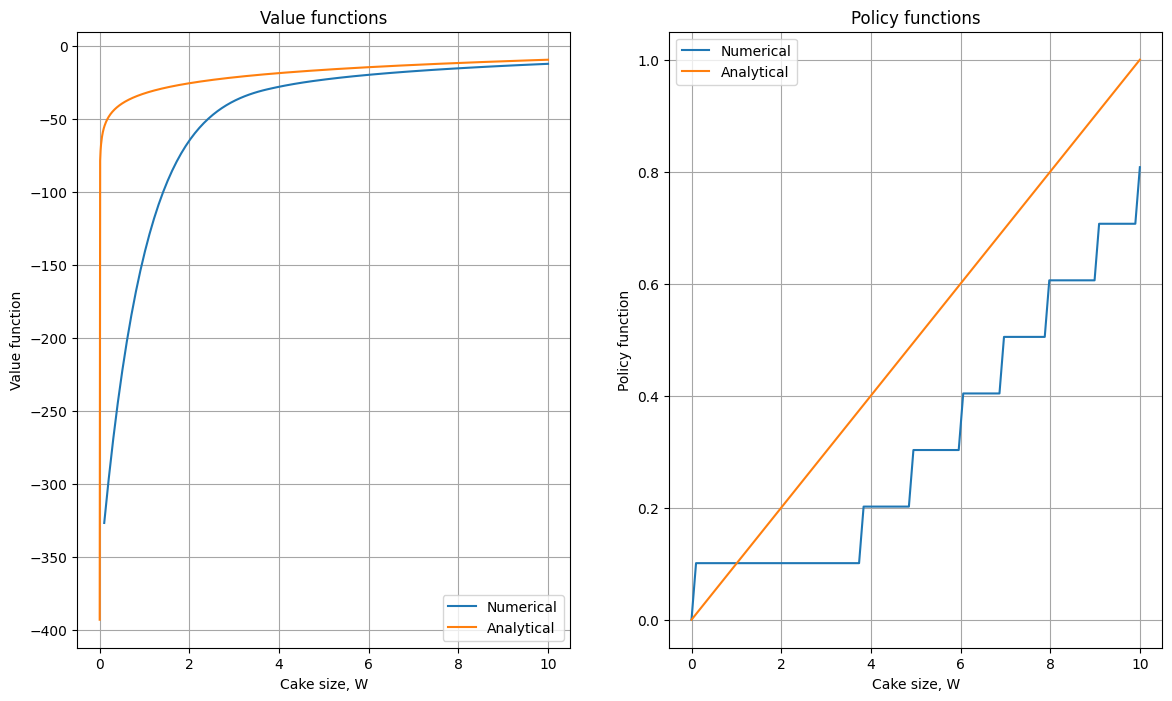
Clear improvement in the accuracy of the solution, but still ways to go!
How to increase the accuracy?
increase the number of grid points, both in state space and especially in choice space
optimize the use of the grid points in the choice space by accounting for the constraints of the model
relocate the state grid points towards the ares of higher curvature of the value function
use a more sophisticated approximation technique
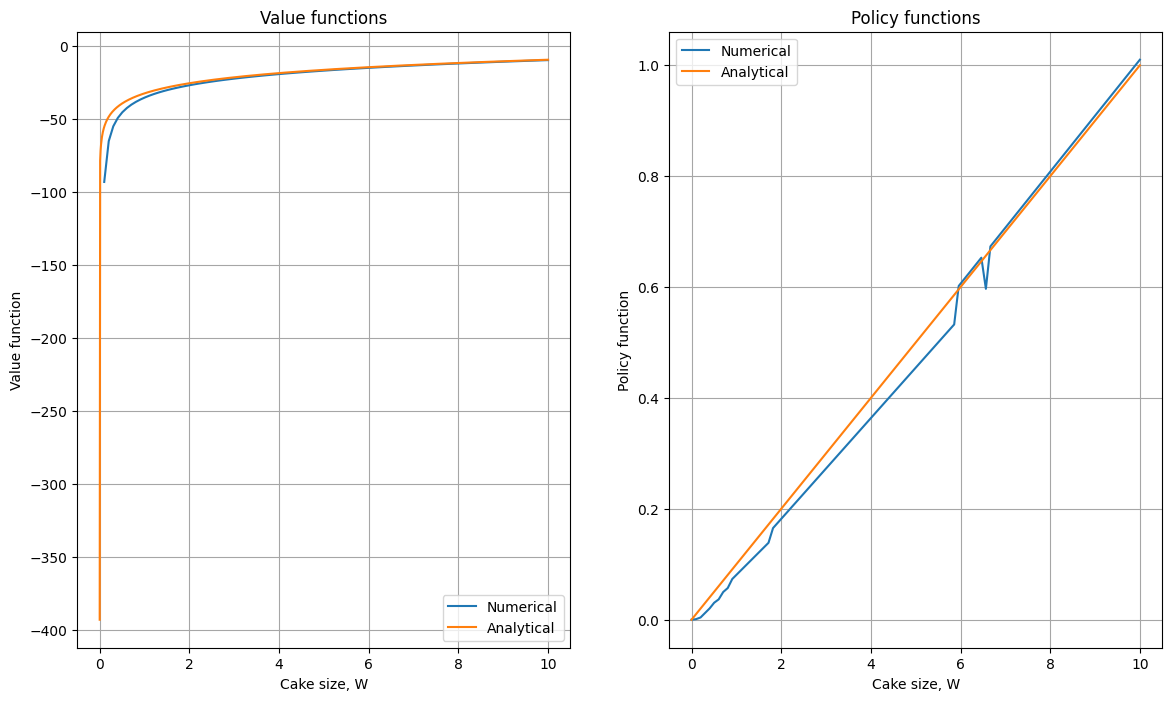
Approach 2: Repeated numerical optimization#
Attack the optimization problem directly and run the optimizer to solve
Advantage: potentially much more accurate solution
Disadvantages:
optimization requires an iterative method run in every point of the state space grid in each time period \(\Rightarrow\) potentially very slow approach
alogorithm has to be robust may fail to converge or get stuck in local maxima
the latter is a severe problem in complicated models (for example, non-convex problems)
Thoughts on appropriate numerical optimization method
For Newton we would need first and second derivatives of \(V_{i-1}\), which is itself only approximated on a grid, so no go..
The problem is bounded, so constrained optimization method is needed
Bisections should be considered
Other derivative free methods?
Quasi-Newton method with bounds?
The Python implementation can make use of scipy.optimize.minimize_scalar(method=’bounded’) which is the
Brent method to find a local minimum.
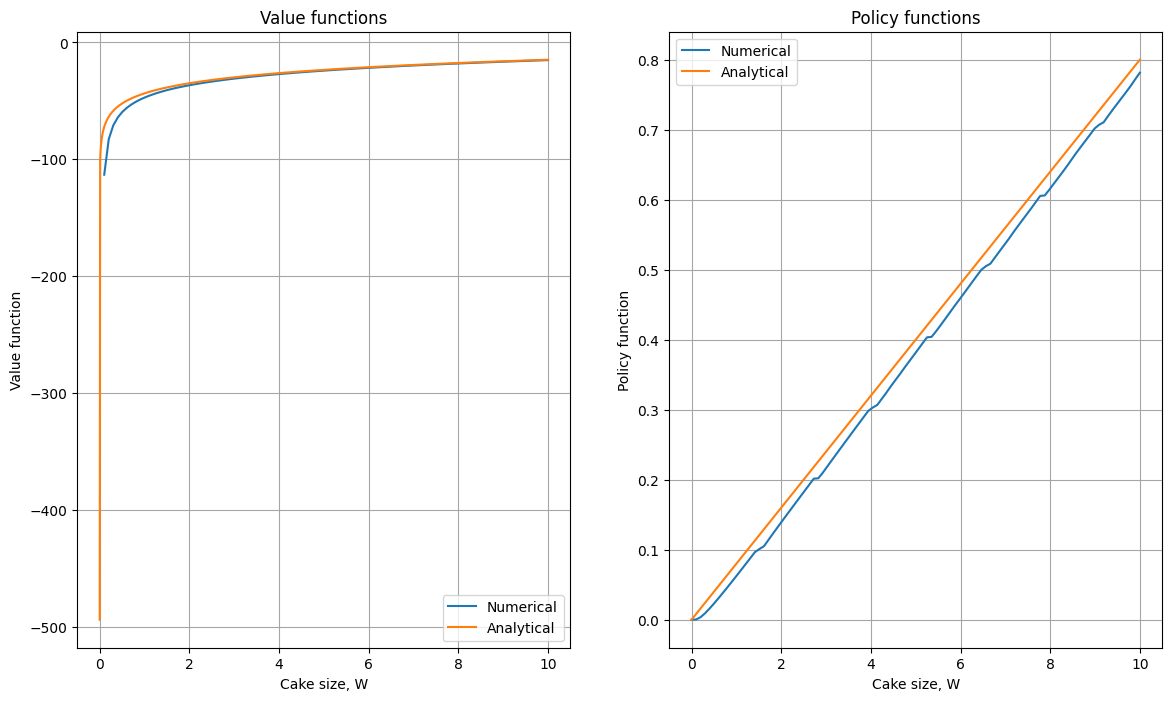
Approach 3: Endogenous gridpoint method#
By far the best available solution method for the consumption-savings model!
fastest and most accurate solution methods for particular problems with continuous choice
finite and infinite horizon, discrete time
applicable to many other important problems
has multiple generalizations which are applicable to a larger class of problems
Main idea: avoid the numerical optimization step in the Bellman equation by constructing the grid of the state variable endogenously based on the first order condition of the problem
In other words, EGM = guess the optimal consumption, and find the point in the state space where the guessed value is indeed optimal.
Euler equation#
The first order condition (FOC) for the cake eating problem is given by
In the same time by the envelope theorem we have
Combining the two equations we realize that \(\frac{1}{c_{t}} = \frac{\partial V(W_{t})}{\partial W_{t}}\), which obviously holds at any \(t\). Thus, we get the Euler equation which characterizes the optimal intertemporal allocation of cake consumption
Given the optimal consumption level in the next period \(c_{t+1}\), we can compute the optimal consumption in the current period \(c_{t}\) as \(c_{t} = c_{t+1} / \beta\).
Full EGM algorithm#
Set a grid on (discretize) post-decision state \(A = W-c\) instead of state \(W\) (how much cake is left for the future after today’s consumption)
Set the initial policy \(c_0(W) = W\) defined over two points \(W \in \{0,\bar{W}\}\) provided linear interpolation in used
Increment iteration counter \(i\) (initialized to 0)
For each point \(A_j\) on the grid over \(A\) do:
Realize that the next period cake size is given by \(W'_j = A_j\)
Compute the optimal consumption in the next period using the previous iteration policy function \(c_{i-1}(A_j)\)
Using the (analytically inverted) Euler equation, compute the optimal level of consumption in the current period \(c_j\)
Compute the endogenous state point \(W_j = A_j + c_j\)
Combine all computed endogenous points in the state space \(W_j\), and their corresponding consumption levels \(c_j\) to build the updated policy function \(c_i(W)\)
Return to step 3, unless convergence achieved (policy functions \(c_i(W)\) and \(c_{i-1}(W)\) are within given tolerance)
Advantages:
no root-finding operations, direct computation instead \( \rightarrow \) fast
Euler equation holds in the generated endogenous state points \( \rightarrow \) accurate
Disadvantages: applies only to particular class of problems
Consumption-savings model (Deaton-Phelps-Carroll)#
What has changed?
New interpretation:
Wealth in the beginning of the period \(t\) is \(M\)
Consumption during the period \( t \) is \( 0 \le c \le M \)
No borrowing is allowed
Discount factor \( \beta \), time separable utility \( u(c) = \log(c) \)
Gross return on savings \( R \), (can be stochastic!)
Constant income \( y \ge 0 \), (can be stochastic!)
This is the cake eating problem when \(R=1\) and \(y=0\)
The stochastic version of the model has to take expectations with respect to the distributions of \(\tilde{R}\) and \(\tilde{y}\) if they are random variables.
we focus on income fluctuations \( \tilde{y} \) and fix \( \tilde{R} \)
let stochastic income \( \tilde{y} \) follow a log-normal distribution with parameters \( \mu = 0 \) and \( \sigma \) to be specified
then \( \tilde{y} > 0 \) and \( \mathbb{E}(\tilde{y}) = \exp(\sigma^2/2) \)
for backward compatibility add \( y=0 \) special case
https://en.wikipedia.org/wiki/Log-normal_distribution
How to compute the expectation?
Quadrature methods, best for up to dimension 3-4
Monte Carlo integration
Both methods transform the integral into a weighted sum
where the terms are the values of the function to be integrated evaluated at certain points (nodes)
and the weights are determined by the integration method
\( x_i \in [a,b] \) quadrature nodes
\( \omega_i \) quadrature weights
See lecture 34 in my Foundations of Computational Economics course, and we will see how it is done in the code.
Euler equation for Deaton model#
FOC: \( \quad u'(c^\star) - \beta R \mathbb{E}_{y} V'\big(R(M-c^\star)+\tilde{y}\big) = 0 \)
Envelope theorem: \( \quad V'(M) = \beta R \mathbb{E}_{y} V'\big(R(M-c^\star)+\tilde{y}\big) \)
Euler equation:
Let \( A \) denote end-of-period wealth = wealth after consumption, that is savings
Timing of the model:
\( A \) contains all the information needed for the calculation of the expected value function in the next period
it is sufficient statistic for the current period state and choice
\( A \) is often referred to as post-decision state
Euler equation with post-decision state can be written as
if policy function \( c(M) \) is optimal, then it satisfies the above equation with \( A = M-c(M) \)
given any policy function \( c(M) \), an updated policy function \( c'(M') \) is given as a parameterized curve
where parameter \( A \) ranges over the interval \( (0,M) \)
This is the basis for the EGM algorithm for the consumption-savings model.
EGM for consumption-savings model#
Fix grid over \( A \)
With given \( c(M) \) for each point on the grid compute
Build the returned policy function \( c'(M) \) as interpolation over computed points \( (M',c') \)
EGM algorithm
Set a grid on (discretize) post-decision state \( A \) instead of state \( M \)
Set the initial policy \( c_0(M) = M \) defined over two points \( M \in \{0,\bar{M}\} \)
Increment iteration counter \( i \) (initialized to 0)
For each point \( A_j \) on the grid over \( A \) perform the EGM step and return the corresponding value of consumption \( c_j \) and the endogenous point of wealth \( M_j = A_j+c_j \)
Combine all computed endogenous points in the state space \( M_j \), and their corresponding consumption levels \( c_j \) to build the updated policy function \( c_i(M) \)
Return to step 3, unless convergence achieved (policy functions \( c_i(M) \) and \( c_{i-1}(M) \) are within given tolerance)
EGM step: Given point \( A_j \) on the grid over \( A \):
Compute the next period wealth \( M'_j = RA_j + \tilde{y} \), replacing \( \tilde{y} \) with quadrature points
Compute the optimal consumption in the next period in all quadrature points, using the previous iteration policy function \( c_{i-1}(\cdot) \)
Compute the marginal utility for each value of consumption, and complete the calculation of the expectation in RHS of Euler equation
Using inverse marginal utility function, compute optimal consumption \( c_j \) in current period, corresponding to the point \( A_j \)
complete the EGM step by computing endogenous state point \( M_j = A_j + c_j \)
EGM for consumption-savings model#
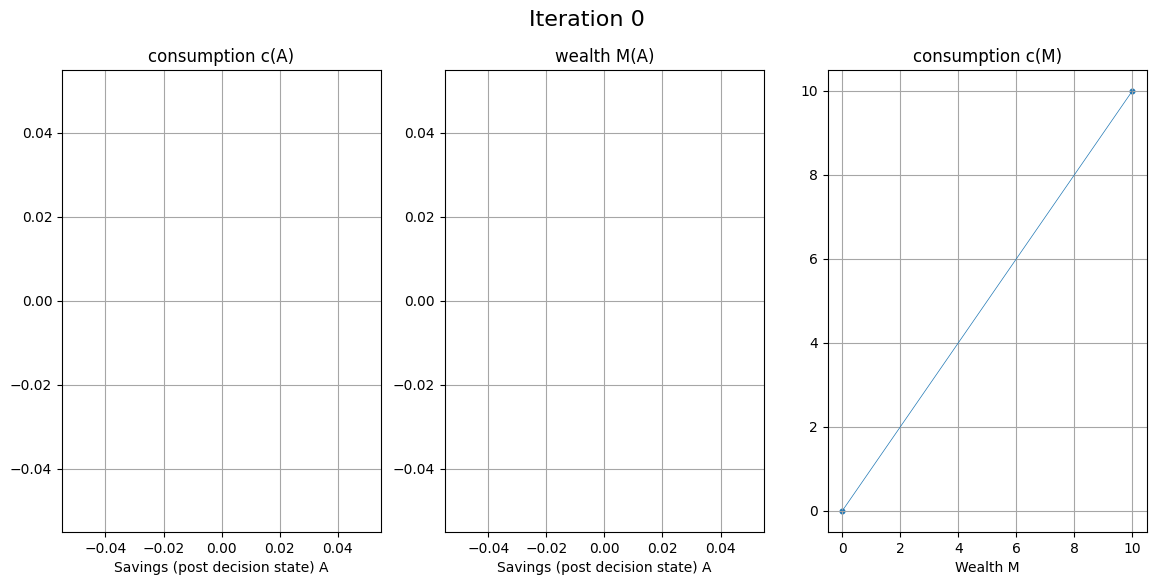
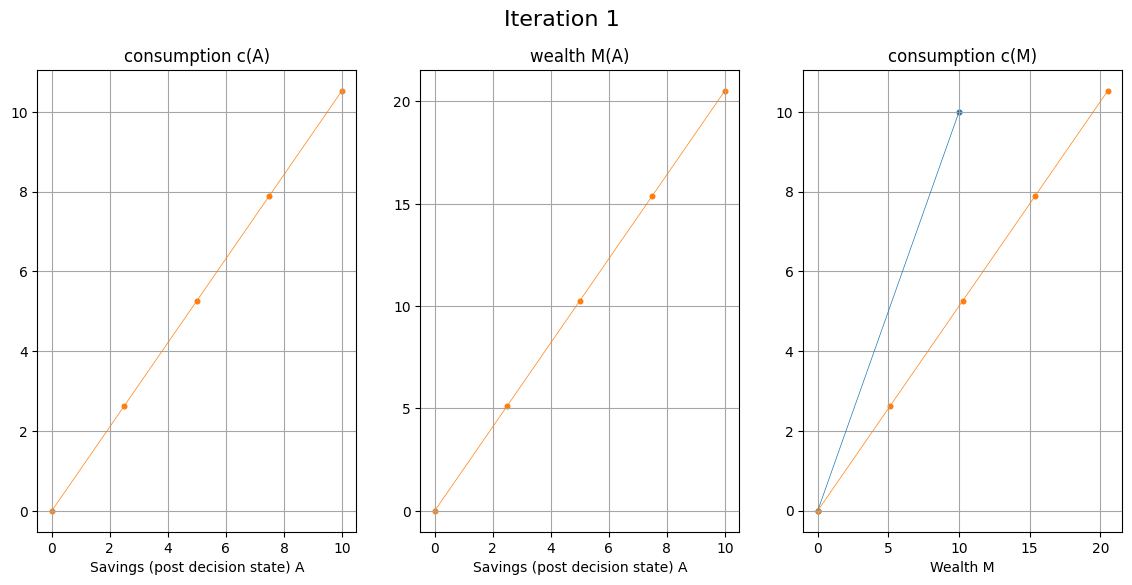
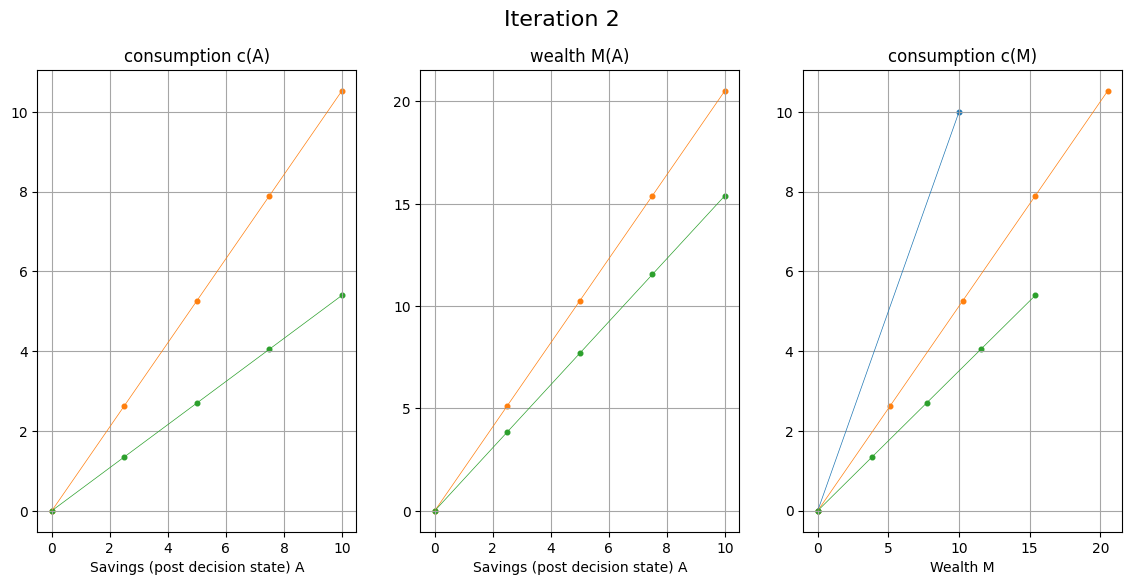
Corner solutions in EGM#
So far only covered the interior solutions where the Euler equation holds
What about the restriction \( 0 \le c \le M \) which is equivalent to \( 0 \le A \le M \)?
By choosing the grid on \( A \) to respect the constraint \( 0 \le A \le M \) EGM only implements interior solutions
Corner solutions must be added with an additional provisions in the code
Lower bound on consumption#
\( c \ge 0 \) is never binding if utility function satisfies
all our usual utility functions like \( \log(c) \) or CRRA utility \( \frac{c^\lambda - 1}{\lambda} \) satisfy this condition
Upper bound on consumption#
If \( c \le M \) is binding, then \( A=0 \), can be computed directly
Proposition If utility function \( u(c) \) in the consumption-savings model is monotone and concave, then end-of-period wealth \( A=M-c \) is non-decreasing in M.
Let \( M_0 = (u')^{-1} \Big( \beta R \mathbb{E}_{y} u'(c(\tilde{y})\big) \Big) \) denote the point that corresponds to \( A=0 \)
Due to the proposition, for all \( M<M_0 \) the end of period wealth must be zero, and thus optimal consumption \( c=M \) is the corner solution
To implement this in the code, we just need to add a 45 degrees segment to the consumption function below \(M_0\)
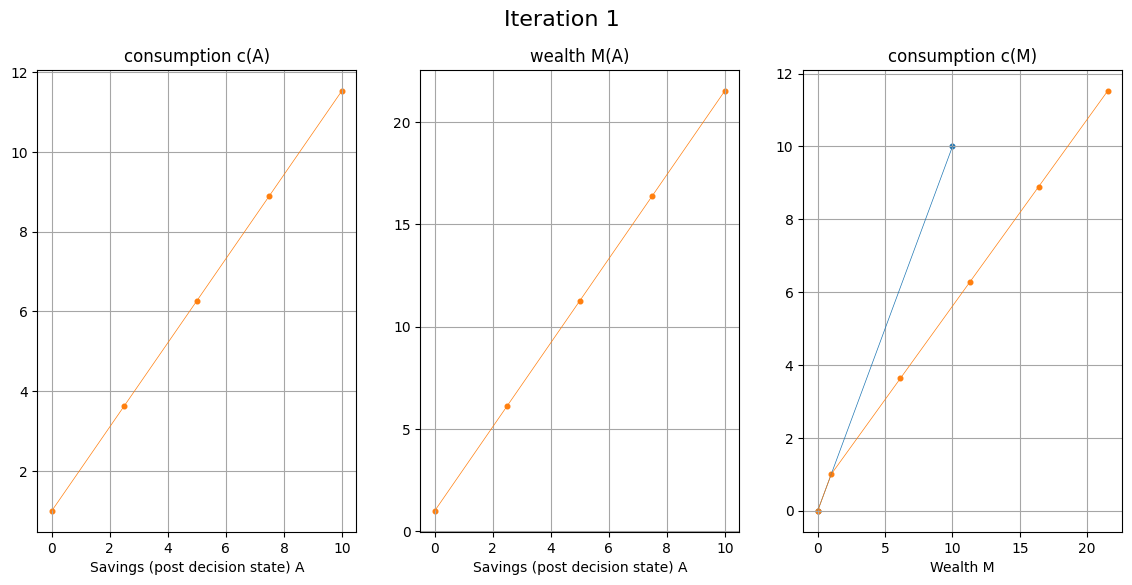
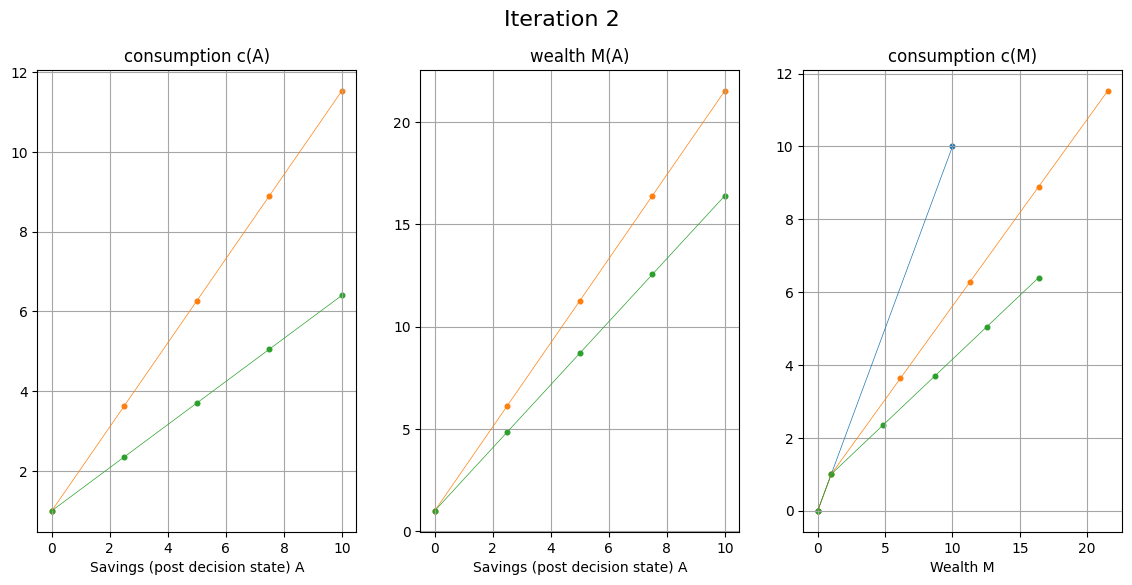
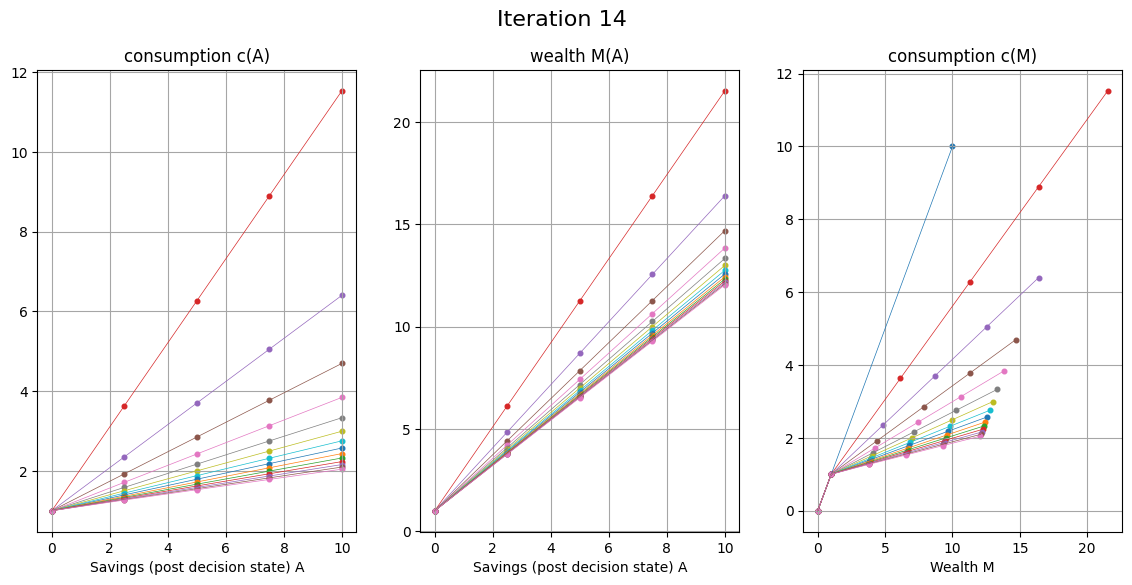
Class of models solvable by EGM#
finite and infinite horizon dynamic models with continuous choice
strictly concave monotone and differentiable utility function (with analytic inverse marginal)
one continuous state variable (wealth) and one continuous choice variable (consumption)
particular structure of the law of motion for state variables (intertemporal budget constraint)
occasionally binding borrowing constraints
can also easily allow additional quasi-exogenous state variables (with motion rules dependent on \( A \) and not \( M \) or \( c \))
Rather small class, although many important models in micro and macro economics are included
Generalizations for multiple dimensions#
Hard because irregular grids in multiple dimensions
📖 Barillas and Fernández-Villaverde [2007] “A Generalization of the Endogenous Grid Method”, Jounrnal of Economic Dynamics and Control
📖 Ludwig and Schön [2018] “Endogenous Grids in Higher Dimensions: Delaunay Interpolation and Hybrid Methods”, Computational Economics
📖 White [2015] “The Method of Endogenous Gridpoints in Theory and Practice”, Journal of Economic Dynamics and Control
📖 Iskhakov [2015] “Multidimensional endogenous gridpoint method: solving triangular dynamic stochastic optimization problems without root-finding operations” + Corrigendum, Economics Letters
📖 Lujan [n.d.] “EGMn: The Sequential Endogenous Grid Method” “
Generalizations for non-convex problems#
Hard because Euler equation is not a sufficient condition any longer!
EGM recovers all solutions of thet Euler equation, thus all local maxima, but additional steps are needed to filter out the suboptimal solutions
Still avoids root-finding operations, thus remains much faster than any alternative methods (which also have to deal with multiple local maxima)
📖 Fella [2014] A Generalized Endogenous Grid Method for Non-Smooth and Non-Concave Problems”, Review of Economic Dynamics
📖 Iskhakov et al. [2017] “The endogenous grid method for discrete-continuous dynamic choice models with (or without) taste shocks”, Quantitative Economics
📖 Druedahl and Jørgensen [2017] “A general endogenous grid method for multi-dimensional models with non-convexities and constraints”, Journal of Economic Dynamics and Control
But if you model fits EGM framework, use it! It is by far the best available method for such problems!
References and Additional Resources
📖 Carroll [2006] “The method of endogenous gridpoints for solving dynamic stochastic optimization problems”, Economics Letters
📖 Iskhakov et al. [2017] “The endogenous grid method for discrete-continuous dynamic choice models with (or without) taste shocks”, Quantitative Economics
📖 Druedahl and Jørgensen [2017] “A general endogenous grid method for multi-dimensional models with non-convexities and constraints”, Journal of Economic Dynamics and Control
Youtube video exlpainer of Brent’s optimization method by Oscar Veliz https://www.youtube.com/watch?v=BQm7uTYC0sg